Computer vision is revolutionizing the way we solve problems in the real world. At Rerun, we have the opportunity to work with developers who are creating innovative computer vision products. One company we want to highlight is PlayReplay.
Accurate line calling for everyone
PlayReplay is bringing advanced technology, previously only seen at tournaments on professional tennis courts, to local courts. Their software can accurately call balls in or out and provides in-depth statistics like serve speed, shot distributions and rpm on your spin. The system is self-sufficient, requiring no specialized personnel for each game. It consists of eight sensors that can be attached to the net post and is operated through a tablet or phone. The solution has received endorsement from the Swedish Tennis Federation and has even replaced human line calling in youth tournaments in Sweden.
A video describing the PlayReplay product
An introspection tool for the entire company
When we spoke with PlayReplay's CTO, Mattias Hanqvist, he had big plans for his visualization stack. He wanted to create an introspection tool that could be used across the organization to improve alignment between developers, support teams, and end users. The tool should allow developers to not only understand the algorithms they're working on, but also experience the product as an end user would. It should also enable the first line support team to gain a deeper understanding of algorithms and malfunctioning systems. Additionally, Hanqvist wanted to build visualizations such that they could easily be adapted from being used by developers to being included in the end product for actual users.
PlayReplay's 3D court view, built using Rerun.
Today, PlayReplay is a part of the Rerun alpha user program and has shifted their internal visualizations over to Rerun. The main user for now is their development team. Going forward the plan is to extend the usage across additional parts of the team.
If you’re interested in getting early access to Rerun, then join our waitlist.
Thirteen years ago, Willow Garage released ROS (the Robot Operating System) and established one of
the standard productivity tools for the entire robotics industry. Back then, as a member of the ROS core team, I worked
on the rosbag storage format and many of the tools it powered. This remains one of the
most rewarding and impactful pieces of software I have developed. Rosbag, and other formats like it, are still widely
used across the robotics industry, serving a crucial role in enabling developers to understand and evaluate their
systems.
Today, the most significant ongoing change in robotics is the use of modern AI in production systems. Creating,
training, and integrating the models that power these systems places new demands on development workflows and tooling.
Still, the core motivations that drove the early evolution of the rosbag format are as present as ever and influence how
we at Rerun think about the next generation of productivity tools for real-world AI. To set the stage for some of that
future work, I’d like to share the original story of how the rosbag format evolved.
A bag of ROS turtles (credit: Midjourney)
Where It All Started
In 2008, I had the great privilege of joining Willow Garage. Willow
Garage was a privately financed robotics research lab with the unique vision of accelerating the entire robotics
industry. The fundamental problem Willow Garage wanted to solve was that robotics research and development lacked a
functional robotics “stack” to build on top of. Not only did this slow down progress since developers were constantly
spending time reinventing the wheel, it dramatically hindered collaboration because developers, left to their own
devices, rarely build compatible wheels. Before Willow Garage, I had worked on early autonomous vehicles as part of the
DARPA Grand Challenge and aerial sensing systems at Northrop Grumman. I was all too familiar with the pain of building
complex systems on top of an ad-hoc home-grown foundation of mismatched tools and libraries.
Willow Garage wanted to solve this problem by building a flexible open-source robotics framework (ROS) and, in parallel,
manufacturing a capable robot tailored to the needs of robotics researchers (the PR2). The idea was to build and give
away identical robots to ten universities alongside several that would be used in-house by a team of researchers at
Willow Garage. By co-developing ROS alongside a shared hardware platform, we could bootstrap an environment where we
could get fast feedback not just on the core functionality but things that would push the envelope of collaboration and
shared development.
One problem common to robotics is that physical systems severely limit the ease of development. Developers are rarely
able to run their code on a live robotic system as quickly and frequently as they might otherwise like to.
If you lack access to a robot or need to share one with others in a lab, you may initially think the robot itself is the
bottleneck. However, even at Willow Garage, where we were building a sizable fleet, running code directly on the robot
was still quite time-consuming. The need for the robot to interact physically with the world makes it far slower than
the average edit-compile-run loop of a software engineer. Moreover, the physical world adds significant non-determinism
to the system, making it challenging to recreate a specific scenario where something unexpected might have happened.
One way of addressing this is to stop using real robots altogether and switch to faster-than-realtime simulators.
Simulators were also a big part of the solution space within ROS and continue to be an area of investment across the
robotics industry today. However, the fidelity of simulators is often limited compared to running in a real system, and
high-fidelity simulators eventually start to run up against similar resource constraints.
The other way of addressing this is to derive as much value as possible from whatever time is available to run code live
on the robot. The initial goal of rosbag was to create this added value by enabling developers to easily record data
about the live robot session, move that data somewhere else, and then later seamlessly playback that recorded data
to make use of it in different ways.
Basic Record and Playback
On the recording side, the core architecture of ROS greatly simplified the design of rosbag. ROS encourages users to
follow a distributed microservices architecture. Systems are split into separable compute elements, called "nodes,"
which communicate over shared busses called "topics." Any node can publish a message to a topic, and other nodes
interested in those messages can receive them.
A ROS network and the rosbag recorder
This architecture makes it straightforward to produce a recording of everything meaningful happening in the system by
listening passively in on all of the available topics. As part of the IPC layer, the publishing nodes are responsible
for serializing the messages into discrete binary payloads. Rosbag can then receive these payloads, associate them with
meta information such as timestamp, topic-name, and message-type, and then write them out to disk. This data was all the
early versions of rosbag needed to contain: a repeating series of timestamped message payloads in a single file. We
called this a ".bag" file.
In contrast to recording, the playback function does this in reverse. Rosbag sequentially iterates through the saved
messages in the bag file, advertises the corresponding topics, waits for the right time, and then publishes the message
payload. Because rosbag directly uses the serialized format to store and transmit messages, it can do this without
knowing anything about the contents. But for any subscribers in the system, the messages look indistinguishable from
those produced by a live system.
This model established a powerful pattern for working with the robots:
Any time a developer ran code on the robot, they would use rosbag to capture a recording of all the topics. Rosbag
could write all of the data directly to robot-local storage. At the end of the session, the recording could be
transferred off the robot to the developer's workstation, put in longer-term storage, or even shared with others.
Developers could later inspect the data using the same visualization and debug tools as the live system but in a
much more user-friendly context. One of the most powerful aspects of this offline playback is that it enabled
additional functionality such as repeating, slowing down, pausing, or stepping through time, much as one might
control the flow of program execution in a debugger.
This offline playback could further be combined with new and modified code to debug and test changes. Playing back a
subset of the bag file, such as the raw sensor data, into new implementations of algorithms and processing models
enabled developers to compare the new output with the initial results. Direct control of the input and the ability
to run in a workstation-local context made this a superior development experience to running code on a live robot.
Developers could sometimes go for multiple days and hundreds of iterations of code changes while working with the data from a single recording.
Enhancements to a Bag-centric Workflow
As developers started doing a more significant fraction of their development using bags instead of robots, we started
running into recurring problems that motivated the next set of features.
Because ROS1 encoded messages using its own serialization format (conceptually similar to google protobuf), it meant
doing something with a bag file required your code to have access to a matching message schema. While we had checks
to detect the incompatibility, playing back a file into a system with missing or incompatible message definitions would
generate errors and otherwise be unusable. To solve this, we started encoding the full text of the message definition
itself into the bag during recording. This approach meant generic tools (especially those written in python, which
supports runtime-loading of message definitions) could still interpret the entire contents of any bag, regardless of its
origin. One tool this enabled was a migration system to keep older bags up-to-date. When changing a message definition,
a developer could register a migration rule to convert between different schema iterations.
Additionally, recording every message in the system meant bags could end up containing millions of messages spread over
tens or hundreds of gigabytes. But often, a developer was only interested in a small portion of the data within this
file when testing their code. Very early versions of the rosbag player allowed a user to specify a start time and
duration for playback. Still, even if rosbag skipped the steps related to reading and publishing, the format required
sequentially scanning through every message in the file to find where to start. To address this, we began including a
time-based index of all the messages at the end of the file. Not only did this allow the reader to jump directly to the
correct place to start playing, but it also made it much easier to only play back a subset of the topics.
During recording, rosbag still wrote records incrementally to the file, just as before. However, when closing the file,
rosbag would append a consolidated copy of the message definitions and indexes at the very end. Since the index is just
a performance optimization for data already written to the file, the rosbag tool could regenerate it by scanning the
file sequentially from the beginning. This structure meant files could still be recovered and re-indexed if a crash
occurred mid-recording -- a vital property for recordings that might take several hours to produce.
More Than Just Playback
Making rosbags easier to migrate and faster to work with ultimately meant developers found themselves with more bags.
The need to filter, split, crop, merge, curate, and share bags became increasingly commonplace. Additionally, users
often wanted a high-level overview of a bag to figure out where to seek during playback. While the existing playback
tool could support these operations crudely, we eventually needed a new approach to working with bags more directly.
We developed another revision of the rosbag format to solve this problem and created new libraries to support a more
direct access model. Most notably, this version of the format introduced an internal partitioning called a "Chunk."
Chunks are blocks of messages, usually grouped by time or message-type and optionally compressed. Each chunk importantly
includes a sub-index describing the messages it contains. Rather than a single index, the end of the bag now had a
collection of Chunk Info records with each chunk's location and higher-level information about its contents.
Overview of the rosbag V2.0 format (not to be confused with the ROS2 bag format)
This format and the new libraries enabled us to build new GUI tools like rxbag that could directly open and view the
bag's contents. These tools included functionality like per-topic overviews of messages over time, thumbnail previews
generated by random access to strategic locations, inline plotting of values from specific topics, and fast scrubbing
both forward and backward in time. At a minimum, the tool could use the included schema to create a preview of any
message in the file with a textual json-like representation. After using these tools to find a location of interest, a
developer could still publish the relevant portion of the stream using the traditional playback model.
These lower-level access libraries also opened up new possibilities. For example, a developer could now write more
"batch-style" offline processing jobs without the constraints of the runtime system. This style of job was more suited
to higher-performance filtering or transformation tasks.
Good Enough for a Generation
And that was when rosbag generally crossed a critical usability threshold. It was good enough for what people needed to
do with it. The rosbag format has remained relatively unchanged since mid-2010 as
a foundational piece of the ROS ecosystem. Although replaced in ROS2 with alternative storage mechanisms, it is still
the recording format for ROS1, which won't see end-of-life until 2025 -- a remarkable 15-year run of powering robotics
data collection, inspection, and playback use-cases.
To summarize, there are a few things that made rosbag truly useful for the ROS community:
It is nearly free to use (if you are using ROS). By taking advantage of existing messages in the system, rosbag
requires no extra code to start making valuable recordings.
Similarly, a powerful playback system also makes it easy to use the data in conjunction with existing algorithms
while bringing additional functionality related to control of time and repeatability.
Each bag exists as a singular self-contained file with no assumptions about the computer, path, or software context
that produced it. You can freely move, save, and share it as an atomic unit. The included schema means the data can
always be extracted, even working with files from older versions.
The built-in index means rosbag tools function efficiently for common use cases, even when dealing with large files.
Direct-manipulation libraries allow developers to process .bag files in alternative ways outside the core ROS
execution paradigm.
More than just a file format, an ecosystem of generic tooling brings convenient support for visualization,
inspection, and file manipulation.
Beyond Rosbag
Perhaps the most controversial aspect of the original rosbag format was the intrinsic dependency on the ROS message
definition format and the ROS framework. On the one hand, this choice meant all users of ROS could more easily work with
any bag file, improving interoperability within the community. On the other hand, this precluded adoption from users
unable to take on such significant dependency. An all too familiar story is startups and research labs, again, rolling
their own rosbag-like format from scratch, precluding interoperability with standardized tools.
As part of a move to better interoperate with commercial use cases, ROS2 transitioned to a generic middleware
architecture supporting alternative transport and message serialization backends. This transition also introduced a
storage plugin system for rosbag instead of a single
definitive format. The initial storage plugin for rosbag2 leveraged sqlite3. While
the sqlite3 storage plugin takes advantage of a mature open-source library and brings more generalized support for
indexing, querying, and manipulating files, it also misses out on some of the original rosbag features. A few downsides
of this direction are that it gives up streaming append-oriented file-writing and lacks self-contained message schemas.
At this point, the most logical evolutionary descendent of rosbag is the open-source MCAP format,
developed by foxglove as both a standalone container format and an alternative storage backend for rosbag2. MCAP
directly adopts many of the original rosbag file format concepts while further adding support for extensible message
serialization. It also cleans up a few of the rough edges, such as being more explicit about separate data and summary
sections, avoiding the need to mutate the rosbag header, and moving to a binary record-metadata encoding.
Further removed from ROS, other formats are similarly motivated by the need for a portable, stream-oriented,
time-indexed file format. For example, the facebook research VRS (Vision Replay System)
format was developed more specifically for AR and VR data-capture use cases
but aims to solve many of the same problems. Rather than using existing serialization formats and generalizing the
schema support, VRS uses its own data layout encoding. While this adds a lot of power to the VRS library regarding data
versioning and performance, it also adds a fair bit of complexity. Similar to the ROS2 approach with sqlite3, VRS
abstracts this complexity behind an optimized cross-platform library. However, this approach makes it challenging to
work with a raw VRS file without using the provided library to process it.
What's Needed for the Future?
Great log-replay tools have become an essential part of building successful robotics and perception systems for the real
world. Formats like MCAP and VRS give us a great foundation to build upon but are unlikely to be the end of this
evolutionary arc.
There have been numerous developments in the years following the design of the rosbag format. An explosion of sensors
and energy-efficient computing has unlocked new possibilities for hardware availability, while AI has gone from
promising to breathtakingly powerful. The opportunities to solve real-world problems with these technologies have never
been greater. At the same time, teams need to be more efficient with their resources and get to market faster.
So what features do the next generation of tools for real-world I need to incorporate?
Capture More than Runtime Messages
The current generations of log-replay tools build on top of schematized “message-oriented” systems like ROS. While this
paradigm makes capturing data along the interface boundaries easy and efficient, it can introduce significant friction
when capturing data from deeper within components or outside the system runtime. Future tools must give developers
enhanced visibility across contexts ranging from core library internals to prototype evaluation scripts.
Easily Express Relationships Between Data Entities
When analytics and visualization tools know about the causal, geometric, and other relationships between data entities,
they can provide developers with powerful introspection capabilities. Making it easy for developers to express these
relationships effectively requires making them first-class citizens of the data model in a way that is difficult to
achieve with current log-replay tools.
Support More General and Powerful Queries
The time-sequential index of events in a system only tells part of the story. To fully understand and explore the
relevant data, developers need access to sophisticated and interactive querying and filtering operations. The next
generation of tools should allow users to compare and aggregate across runs or any other dimension easily.
Robotics and AI/ML Workflows are Merging
Established practices from the robotics industry are mixing with workflows from the AI/ML community. This will continue
and is necessary for achieving widespread success with AI in the real world. Both traditions will need to learn from the
strengths of the other.
At Rerun, we’re building a new generation of tools informed by these old lessons and new demands. Much like in the early
days of ROS, it’s clear there’s an opportunity to transform the workflows of a new generation of teams. As with the
development of rosbag, the steps we take along the way will need to be iterative and incremental, driven by real
feedback and use.
In order to work as closely as possible with the community, we plan to open source Rerun in the near future. If you're
excited about being a part of that journey, sign up for our
waitlist to get early access or a
ping when it’s publicly available.
Computer vision is a powerful technology solving real problems in the real world, already today. It holds the potential to significantly improve life on earth over the next decades. At Rerun we have the privilege to work directly with developers that are building that future. From time to time we will introduce companies building computer vision products for the real world. The first company we want to introduce is biped.
Translating vision to audio
biped is a Swiss robotics startup that uses self-driving technology to help blind and visually impaired people walk safely. The shoulder harness they develop embeds ultra wide depth and infrared cameras, a battery and a computation unit. The software running on the device estimates the positions and trajectories of all surrounding obstacles, including poles, pedestrians or vehicles, to predict potential collisions. Users are warned with 3D audio feedback, basically short sounds similar to the parking aid in a car, that convey the direction, elevation, velocity and type of obstacle. The device also provides GPS instructions for a full navigation assistance.
biped is one of the most advanced navigation devices for pedestrians, and seeks to improve the independence of blind and visually impaired people across the world.
A demo of biped being used out in the wild, including audio feedback users receive
A complex pipeline with complex data
On a high level, biped’s software does the following in real-time:
Sequentially acquire image and depth data from all cameras, fusing the different inputs into a single unified 3D representation
Run perception algorithms such as obstacle segmentation or object detection
Prioritize the most important elements based on risks of collision
Create 3D audio feedback to describe the prioritized elements of the environment
A small change anywhere in the pipeline can affect the performance of downstream tasks and thus the overall performance significantly. For example, the quality of environment understanding strongly affects the prioritization algorithm. biped employs different strategies to counter this problem and to make development as easy as possible. One of them is to visualize intermediate steps of the pipeline with Rerun. This allows the development team to get a quick understanding of how each change affects the whole pipeline.
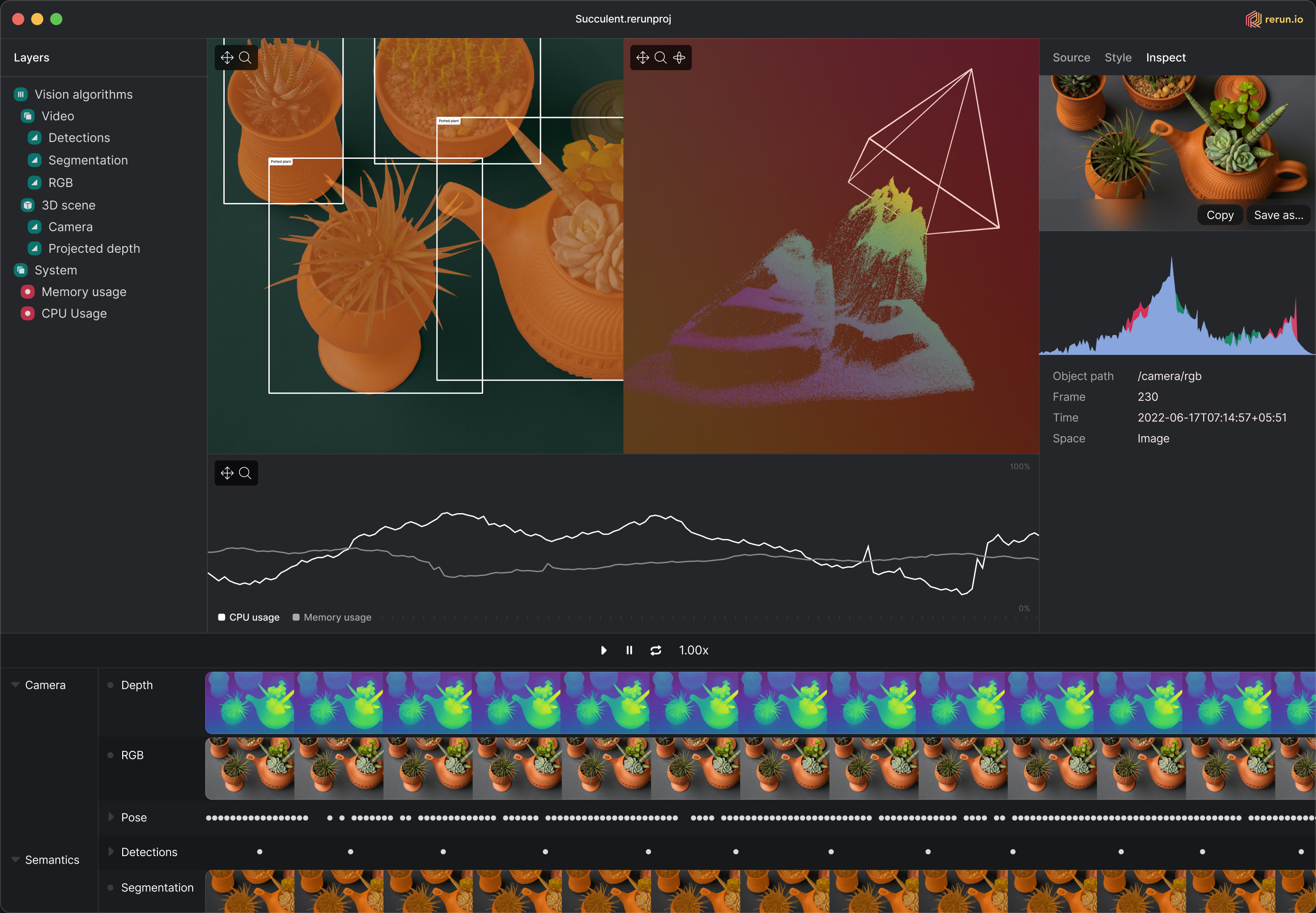
A visualization of biped’s perception algorithms, built using Rerun.
biped is a part of the Rerun alpha user program and has recently shifted their internal visualizations to Rerun.
If you’re interested in getting early access to Rerun, then join our waitlist.
In his 2014 talk Seeing Spaces, Bret Victor envisioned an environment where technology becomes transparent, where you effortlessly see inside the minds of robots as you build them. This is the dream of everyone building computer vision for the physical world, and is at the core of what we're building at Rerun.
Like most interesting people Bret is hard to summarize, but you might say he’s a designer/engineer turned visionary/researcher that talks a lot about interfaces and tools for understanding. He's on a life-long mission to change how we think and communicate using computers.
You know a body of work is special when just taking a small aspect of it, potentially out of context, still produces great ideas. This is without a doubt true of Bret Victor's work, which has been the inspiration for Figma, Webflow, Our World in Data, and many others.
The overlooked inspiration behind Rerun
The best articulation I know of the need to see inside your systems, particularly those with a lot of internal complexity, comes from the talk Seeing Spaces. It’s seldomly referenced but I keep going back to it and am always struck by how prescient it was back in 2014.
The context of the talk is roughly the future of maker spaces. In it he makes two main points:
For a growing number of projects with embedded intelligence (robotics, drones, etc), the main challenge isn’t putting them together, but understanding what they are doing and why. What you need here are seeing-tools and we don't really have many of those.
If you’re really serious about seeing, you build a dedicated room (think NASA’s mission control room). We therefore need Seeing Spaces. These spaces would be shared rooms that embed all the seeing-tools you need, similar to how maker spaces have a shared set of manufacturing equipment.
NASA's Shuttle Control Room is built for serious seeing. Photo Credit: NASA
A physical space for seeing is interesting, and if you follow Bret’s work you can see the lineage from this, through The Humane Representation of Thought, to his current project Dynamicland. Whether or not creating a dedicated physical space is the right way to go, for most teams it’s not practical or the top priority. The first problem is getting “regular” software seeing-tools in place that make it easier to build and debug intelligent systems.
This is essentially what we are doing at Rerun. We are building software based seeing-tools for computer vision and robotics. For teams that want to go all the way to Seeing Spaces, the building blocks they need will all be there.
What is a seeing-tool?
Seeing-tools help you see inside your systems, across time and across possibilities. Seeing inside your systems consists of extracting all relevant data, like sensor readings or internal algorithm state, transmitting it to the tool, and visualizing it. This should all be built in and require no additional effort.
Seeing across time means visualizing whole sequences, and making it possible to explore them by controlling time. These sequences could either take place in real world time, or in compute time like steps in an optimization. Seeing across possibilities means comparing sequences to each other, for example over different parameter settings. When training machine learning models, this is usually called experiment tracking.
In essence, a seeing tool is an environment that lets you move smoothly from live interactive data visualization to organizing and tracking experiments.
Principles for a computer vision focused seeing-tool
Every team that builds computer vision for the physical world needs tools to visualize their data and algorithms, and currently most teams build custom tools in-house. Prior to Rerun, we've built such tools for robotics, autonomous driving, 3D-scanning, and augmented reality. We believe there are a couple of key principles we need to follow in order to build a true seeing-tool that can unlock progress for all of computer vision.
Separate visualization code from algorithm code
It's tempting to write ad-hoc visualization code inline with your algorithm code. It requires no up-front investment; just use OpenCV to paint a picture, and show it with cv.imshow. However, this is a mistake because it makes your codebase hard to work with, and constrains what and where you can visualize.
If you instead keep your visualizations separate, it both keeps your codebase clean and opens up for more powerful analysis. It works for devices without screens and you can explore your systems holistically across time and different settings.
You can't predict all visualization needs up-front
For computer vision, visualization is deeply intertwined with understanding. As developers build new things, they will invariably need to visualize what they are doing in unforseen ways. This means it needs to be easy to add new types of visualizations without having to modify the visualizer or the supporting data infrastrucutre. This means we need powerful and flexible primitives and easy ways to extend the tools.
When prototyping, a developer should for instance be able to extend a point cloud visualization with motion vectors without recompiling schemas or leaving their jupyter notebook.
The same visualizations from prototyping to production
Algorithms tend to run in very different environments as they progress through prototyping to production. The first prototype code might be written in a Colab notebook while the production environment could be an embedded device on an underwater robot. Giving access to the same visualizations across these environments makes it easier to compare results and removes duplicated efforts.
The increased iteration speed this has can be profound. I've personally experienced the time needed to go from observed problem in production, to diagnosing and designing a solution, and finally deploying a fix, decreasing from days down to minutes.
Why do seeing-tools matter?
Seeing-tools are needed to effectively understand what we are building. They enable our work to span from tinkering to doing experimental science. It’s currently way too hard to build great computer vision based products for the physical world, largely due to the lack of these tools.
The recent progress in AI has increased the amount of people that work on AI powered products. As any practitioner in the field knows, the process of building these products is less like classic engineering, and more a mix of tinkering and experimental science. As we as a community start deploying a lot more computer vision and other AI in real world products, great seeing-tools will be what makes products succeed. At Rerun we made it our mission to increase the number of sucessful computer vision products in the physical world. And to get there we're building seeing-tools.
I've been a programmer for 20+ years, and few things excite me as much as Rust. My background is mostly in C++, though I have also worked in Python and Lua, and dabbled in many more languages. I started writing Rust around 2014, and since 2018 I've been writing Rust full time. In my spare time I've developed a popular Rust GUI crate, egui.
When I co-founded Rerun earlier this year, the choice of language was obvious.
At Rerun we build visualization tools for computer vision and robotics. For that, we need a language that is fast and easy to parallelize. When running on desktop we want native speed, but we also want to be able to show our visualization on the web, or inline in a Jupyter Notebook or IDE.
By picking Rust, we get speed that rivals C and C++, and we can easily compile to Wasm. By using Rust for both our frontend and backend, we have a unified stack of Rust everywhere, simplifying our hiring.
Speaking of hiring, we hoped that by picking Rust, we would attract more high quality developers. This bet on hiring turned out even better than we had hoped.
Sure, but why, really?
Ok you got me! Those are only a part of the reasons we chose Rust. If I'm honest, the main reason is because I love Rust.
I believe Rust is the most important development in system programming languages since C. What is novel is not any individual feature ("Rust is not a particularly original language"), but the fact that so many amazing features have come together in one mainstream language.
Rust is not a perfect language (scroll down for my complaints!), but it's so much nicer than anything else I've used.
I'm not alone in loving Rust - Rust has been the most loved language in the Stack Overflow Developer Survey for seven years straight. So what are the features that make me love Rust so much?
Safety and speed
"Wait, that's two features!" - well yes, but what is novel is that I get both.
To be clear: what I'm talking about here is memory safety, which mean handling array bounds checks, data races, use-after free, segfaults, uninitialized memory, etc.
We've had fast languages like C and C++, and then we've had safe languages like Lisp, Java, and Python. The safe languages were all slower. Common wisdom said that a programming language could either be fast or safe, but not both. Rust has thoroughly disproved this, with speeds rivaling C even when writing safe Rust.
What's even more impressive is that Rust achieves safety and speed without using a garbage collector. Garbage collectors can be very useful, but they also tend to waste a lot of memory and/or create CPU spikes during GC collection. But more importantly, GC languages are difficult to embed in other environments (e.g. compile to Wasm - more on that later).
The big innovation leading to this "fast safety" is the borrow checker.
The borrow checker
The Rust Borrow Checker has it's roots in the Cyclone research language, and is arguably the most important innovation in system program languages since C.
The gist of it is: each piece of data has exactly one owner. You can either share the data or mutate it, but never both at the same time. That is, you can either have one single mutating reference to it, OR many non-mutating references to the data.
This is a great way to structure your program, as it prevents many common bugs (not just memory safety ones). The magic thing is that Rust enforces this at compile-time.
A lot of people who are new to Rust struggle with the borrow checker, as it forbids you from doing things you are used to doing in other languages. The seasoned Rustacean knows to cut along the grain, to not fight the borrow checker, but to listen to its wisdom. When you structure your code so that each piece of data has one clear owner, and mutation is always exclusive, your program will become more clear and easy to reason about, and you will discover you have fewer bugs. It also makes it a lot easier to multi-thread your program.
Enums
Rust's enums and exhaustive match statement are just amazing, and now that I'm using them daily I can barely imagine how I could live without them for so long.
Consider you are writing a simple GUI that needs to handle events. An event is either a keyboard press, some pasted text, or a mouse button press:
This is extremely verbose and it is easy to forget an error.
In languages with exceptions, like C++, Java, and Python, you instead have the problem of invisible errors:
auto result = foo().bar();
As a reader, I can't see where potential errors can occur. Even if I look at the function declaration for foo and bar I won't know whether or not they can throw exceptions, so I don't know whether or not I need a try/catch block around some piece of code.
In Rust, errors are propagated with the ? operator:
let result =foo()?.bar()?;
The ? operator means: if the previous expression resulted in an error, return that error. Failure to add a ? results in a compilation error, so you must propagate (or handle) all errors. This is explicit, yet terse, and I love it.
Not everything is perfect though - how error types are declared and combined is something the ecosystem is still trying to figure out, but for all its flaws I find the Rust approach to error handling to be the best I've ever used.
Scoped resource management
Rust will automatically free memory and close resources when the resource falls out of scope. For instance:
{letmut file =std::fs::File::open(&path)?;letmut contents =Vec::new();
file.read_to_end(&mut contents)?;
…
// when we reach the end of the scope,// the `file` is automatically closed// and the `contents` automatically freed.}
If you're used to C++ this is nothing new, and it is indeed one of the things I like the most about C++. But Rust improves this by having better move semantics and lifetime tracking.
This feature has been likened to a compile-time garbage collector. This is in contrast with a more common runtime garbage collected language, where memory is freed eventually (at some future GC pass). Such languages tend to use a lot more memory, but worse: if you forget to explicitly close a file or a socket in such a language, it will remain open for far too long which can lead to very subtle bugs.
Wasm
I find WebAssembly (or Wasm for short) a very exciting technology, and it probably deserves a blog post on its own. In short, I am excited because with Wasm:
I can write web apps in another language than JavaScript
I can write web apps that are fast
I can safely and efficiently sandbox other peoples' code
So what does Wasm have to do with Rust? Well, it is dead easy to compile Rust to Wasm - just pass --target wasm32-unknown-unknown to cargo, and you are done!
And then there is wasmtime, a high performance runtime for Wasm, written in Rust. This means we can have fast plugins, written in Rust, compiled to Wasm, running in our tool. Rust everywhere!
Traits
The Rust trait is really nifty as it is the interface for both run-time polymorphism and compile-time polymorphism. For instance:
traitFoo{fndo_stuff(&self);}// Run-time polymorphism (dynamic dispatch).// Here `Foo` acts like an Java interface or a abstract base class.fnruntime(obj:&dynFoo){
obj.do_stuff();}// Compile-time polymorphism (generics).// Here `Foo` acts as a constraint on what types can be passed to the function// (what C++ calls a "concept").fncompile_time<T:Foo>(obj:&T){
obj.do_stuff();}
Tooling
Rust has amazing tooling, which makes learning and using Rust a much more pleasant experience compared to most other languages.
First of all: the error messages from the compiler are superb. They point out what your mistake was, why it was a mistake, and then often point you in the right direction. The Rust compiler errors are perhaps the best error messages of any software anywhere (which is fortunate, since learning Rust can be difficult).
Then there is Cargo, the Rust package manager and build system. Having a package manager and a build system for a language may seem like a low bar, but when you come from C++, it is amazing. You can build almost any Rust library with a simple cargo build, and test it with cargo test.
Rust libraries are known as crates (and can be browsed at crates.io). Though the ecosystem is nascent, there is already a plethora of high quality crates, and trying out a crate is as easy as cargo add. There is of course some legitimate worry that the Rust crate ecosystem could devolve into the crazy left-pad world of npm, and it is something to be wary about, but so far the Rust crates keep an overall high quality.
And then there is the wonderful rust analyzer which provides completion, go-to-definition, and refactoring to my editor.
Rust documentation is also really good, partially because of the effort of its writers, partially because of the amazing tooling. cargo doc is a godsend, as are doc-tests:
/// Adds two numbers together.////// ## Example:/// ```/// assert_eq!(add(1, 2), 3);/// assert_eq!(add(10, -10), 0);/// ```fnadd(a:i32, b:i32)->i32{
a + b
}
The compiler will actually run the example code to check that it is correct! Amazeballs!
The bad
It's not all unicorns and lollipops. Rust has some pretty rough edges, and may not be for everyone.
It's not a simple language
Rust is difficult, and it takes a while to learn. Even if you know C and some functional programming, you still need to learn about the borrow checker and lifetime annotations. Still, I would put Rust as both simpler and easier than C++.
Compile times
This is unfortunately something Rust has inherited from C++. Things are bad, and are only slowly getting better, and I doubt it will ever be fast as e.g. Go.
Noisy syntax
You will see a lot of <'_> and ::<T> in Rust, and it ain't always pretty (but you get used to it).
Floating point behavior
f32 and f64 does not implement Ord. This means you cannot sort on a float without jumping through a lot of hoops, and this is very annoying. I wish the float would just use total ordering and take the performance hit.
Same with Hash, which f32 and f64 also doesn't implement.
Thankfully there is the ordered-float crate, but the ergonomics of using a wrapped type isn't great.
Still lacking a lot of libraries
The Rust crate ecosystem is good, but C and C++ has a huge head start and it will take a long time for Rust to catch up. For us at Rerun, that pain is most urgently felt in the lack of libraries for scientific computing and computer vision, as well as the lack of mature GUI libraries.
Flawed, but improving
Five years ago my gripes with Rust were much longer. Rust is steadily improving, with a new release every six weeks. This is an impressive pace, especially since there are no breaking changes.
Conclusion
At the end of the day, a programming language is a tool like any other, and you need to pick the right tool for the job. But sometimes, the right tool for the job is actually the tool you love the most. Perhaps that is exactly why you love it so much?
In many ways, using C++ for the engine, Go for the backend, and JS for the frontend would have been the "safe" choice. We could have made use of the many great C++ libraries for linear algebra and computer vision, and we could have used one of the many popular and excellent frontend libraries for JS. In the short term that might have been the right choice, but it would have severely limited what we could accomplish going forward. It would have been a bet on the past. At Rerun, we are building the tools of the future, and for that we need to be using the language of the future.
Hi! My name is Emil, and I’m a developer with a passion for Rust, dev tools, user interfaces, and climbing. I’m also the creator and maintainer of a couple of open source projects, including egui.
A few months ago, two friends and I co-founded Rerun. We are building a brand new kind of visualization tool for companies working in computer vision. I am extremely excited by this - not only is it a fun thing to build, I also believe it will have a huge, positive impact on the world.
We’ve raised some money, and now we are looking to hire a founding team of great developers to build the first version of our product.
Rerun’s mission
I met my co-founders Niko and Moritz at a computer vision and 3D scanning company where we wrote some really cool in-house visualization tools. We used these tools to quickly iterate when prototyping new algorithms, investigating weird corner cases, and to troubleshoot our deployed scanners. These tools were critical to our success, but took a lot of effort to write. We’ve since learned that all successful computer vision companies build their own in-house visualization tools. This costs them time and effort, and produces tools that aren’t as good as they should be. We want to change that!
20 years ago, if you had an idea for a game, you had to first write a game engine. This stopped most people, and slowed down the rest. Today there are reusable game engines such as Unity and Unreal, and there has been an explosion of great games coming from thousands of studios and indie developers. At Rerun, we are going to write a reusable visualization toolbox for the entire computer vision industry.
Computer vision is going to diagnose illnesses, enable blind people to read street signs, replace insecticides with bug-zapping lasers, power autonomous drones that do repairs in remote and dangerous areas, and on and on. Computer vision is on the cusp of revolutionizing the world, and Rerun will be at the heart of it.
This is what I have been working on for the last two months at https://t.co/jJk7c21KNv!rerun is a visualization tool for developers working with computer vision, robotics, or anything 2D/3D pic.twitter.com/Epw2et4ZXg
A developer starts by using our logging SDK (for C++, Python, Rust, …) to log rich data as easy as they would log text. Rich data includes images, meshes, point clouds, annotations, audio, time series, and so on.
The logs are transformed and cached by a server which sits between the logging SDK and our viewer.
The viewer is an app that can run both natively and in the browser. It can view the logs live, but also recordings. You can scrub time back and forth and compare different runs, and you can customize the viewer to suit your needs.
For the first year we will be working closely with a few select customers, and we will select the customers that are doing the coolest things!
Working at Rerun
We are going to be a small, tight team, working together to build a great product of the highest quality. We believe in being helpful, curious, honest, and never settling for something less than great.
We are very ambitious. This will be difficult, so you need to be good at your job.
We are looking to hire experienced developers who can make their own decisions while also being part of a collaborative team. We want to create a workplace where you can do your life’s best work and learn new things, and also have a family and hobbies.
We are a distributed company with a remote-first culture. The founders are based in Stockholm, Sweden. We expect everyone on the team to be available for discussions and meetings every weekday 13-17 CET. We plan to get the entire team together for a full week once a quarter.
We will pay you a competitive salary with six weeks of paid vacation. You will also be offered an options/equity package. We will pay for whatever hardware and software you need to do your job. You can of course use the OS and editor you feel most comfortable in.
What are the skills we are looking for?
We are creating tools that are extremely easy to use, that look beautiful, and that run butter smooth. We want Rerun to become the kind of tool that you would switch jobs just to be able to use.
We are looking for people who enjoy being helpful to colleagues, customers, and to the open source community.
We are an open core company, so most of what you do the first few years will be open source. You will be using a lot of open source libraries and should be able and willing to contribute to them via issues and PR:s. Any open source experience is a plus.
We expect you to write clean, readable code, intuitive API:s, and good documentation. Communication skills are essential!
We are building everything in Rust, so you should either know some Rust or have the desire and ability to learn it. If you already know C++ or C, you should be fine. Why Rust? Rust is modern and fast, but most importantly: it runs anywhere. We can have the same code run on desktop, the cloud, on edge devices and in the browser.
The Rust borrow checker may be the biggest advance in systems programming language design since C was invented 50 years ago.
It’s great if you have a sense of how images and audio are represented by a computer and a good grasp on linear algebra and statistics.
Any experience building dev-tools is a big plus.
We’re building tools for the computer vision industry, including robotics, drones and self-driving cars. Any experience in relevant fields is a plus, but not a requirement. Knowledge of ROS is also a plus.
We are also very interested in different perspectives, so if you have a different background or experiences than the founding team, you should also apply!
Finally, we want those that have a desire to make a deep, positive impact on the world.
Roles
There are a few roles we need to fill, with a lot of overlap between them. You do not need to fit snugly into a role to apply! You also don’t need to tick all of the boxes - you will perhaps bring other talent to the table which we haven’t foreseen the need for!
We are building a UI that is intuitive, beautiful, and responsive. Any experience building editors (video, audio, CAD, …) is a big plus. The UI will be written in Rust. It will be compiled to WASM and run in a browser, so knowledge of web programming is also a plus.
The viewer needs to be able to scroll through and filter big datasets in real-time, so we are looking for people who know how to write fast code. You should have a good sense of how a CPU works. It is a big plus if you have built game engines or other high-performance real-time apps, as is any experience of threading or SIMD.
We need a graphics engineer who can build a renderer that can run in a browser and also leverage the full performance of the GPU on the desktop. This means the graphics must not only look good, it must also scale. We will likely write the renderer on top of wgpu.
We are writing a high-performance server that needs to index and cache large amounts of visualization data. Experience with databases is a plus here, as is knowledge of tokio or other async code.
We are building a Python SDK for logging visualization data. For this, we want someone with experience building quality Python libraries, preferably someone with experience with OpenCV, PyTorch, Tensorflow, and other Python libraries that we are likely to integrate with.
We are also building a C++ SDK, and here we want someone that feels comfortable with building a C++ library with all that entails. Our C++ SDK needs to be able to run on edge devices too, so experience with embedded software is a plus. Both the Python and C++ SDK:s will be interfacing with Rust over FFI.
Join us!
You can read more about or roles on our jobs page. Even if no single role fits you perfectly, don’t worry - just apply for the role that is closest!
We’re looking forward to hearing from you! ❤️
edited on 2022-07-05 to reflect that we now accept remote candidates
My career-long obsession with computer vision started with a long distance relationship back as an undergraduate. Over countless hours on Skype, we missed looking each other in the eyes. Because the camera is outside the screen, you always look just past each other. I figured it should be solvable with some math and code, so I decided to learn computer vision to fix it - turns out that was much harder than I thought. I’ve been hooked on solving problems with computer vision ever since.
More than a decade later I’ve started Rerun to build the core tools that are missing for computer vision teams to make their products successful in the physical world. My co-founders are two of the most amazing people I know, both old colleagues and friends, Moritz Schiebold and Emil Ernerfeldt. At Rerun we’re building visualization infrastructure for computer vision in the physical world. AI and computer vision has an incredible potential to improve life on earth and beyond. We believe the deployment of this technology needs to happen much much faster.
In 2012 as I was taking Stanford’s Introduction to Computer Vision class with Fei-Fei Li, I had mixed emotions. My mind was opening to the incredible possibilities that computer vision could unlock if it worked, but I also found that in practice it mostly didn’t.
After graduation I joined a 3D body-scanning startup called Volumental, right at the top of the 3D hype cycle. Most of that batch of 3D computer vision startups folded or got acqui-hired, but Volumental persevered. Moritz was the CEO back then and ran a tight ship. We made it through sheer determination to stay alive, an unreasonably strong tech team, and critically to this story, fantastic tooling.
In the early days, we were hand coding each visualization. Doing so was costly in both effort and code complexity so we did as little as we could get away with. What we didn’t know yet was how much everything we didn’t see slowed us down.
When Emil joined us from the gaming industry, he brought a critical–and very different– perspective and skillset. He would start out building an interactive app that visualized everything before touching the actual problem. Visualization Driven Development if you will. Because most of us weren’t strong graphics programmers, Emil built a framework that made it dead simple to build these apps by just providing the data. The increased iteration speed this gave us was key to shipping a product that actually worked, years before any viable competitor, and clearly winning that market.
Think about the map a self-driving car is building: it shows you where the car thinks it is relative to all other objects. You can just look at that and immediately understand how the car’s software is reasoning. You can also quickly understand where it might be wrong. While engineers need more detail, customers and the broader team also need this understanding.
A common misconception is that the rise of deep learning in computer vision makes visualization less important, since models are trained end-to-end and are effectively black boxes. In fact, the opposite is true. Powerful deep learning models make vastly more problems feasible to solve. For all but the simplest applications in the physical world, these models are just components of larger systems. More powerful models also enable more complex behavior that those building the products need to understand. Visualization for computer vision is becoming significantly more important.
Companies like Scale.ai, Weights & Biases, and Hugging Face have made deep learning easier by tackling dataset labeling, experiment tracking, and using pre-trained models. Unfortunately, the toolset for rapid data capture and visualization that was so critical for Volumental, still isn’t broadly available. Every computer vision company building for the physical world currently needs to build it in-house. Many make due with ineffective tools because of the high cost of development. We’re fixing that.
Over the past decade computer vision research has progressed faster than anyone could have imagined. At the same time, real world problems haven’t been solved at nearly the same rate. The expected revolutions in fields like autonomous vehicles, agriculture, manufacturing, augmented reality, and medical imaging are all behind schedule. With the right tools for iterating on these products quickly, we can speed up that deployment by orders of magnitude. More projects will get off the ground and big projects will go faster.
Getting this right is a huge undertaking and to get started we’ve just raised a $3.2M pre-seed round from Costanoa Ventures, Seedcamp, and amazing angels from all over computer vision. I couldn’t be more excited for this opportunity to help our field truly improve life on earth over the decade ahead!
 A bag of ROS turtles (credit: Midjourney)
A bag of ROS turtles (credit: Midjourney)
 A ROS network and the rosbag recorder
A ROS network and the rosbag recorder Overview of the
Overview of the  Overview of the
Overview of the  Overview of the
Overview of the 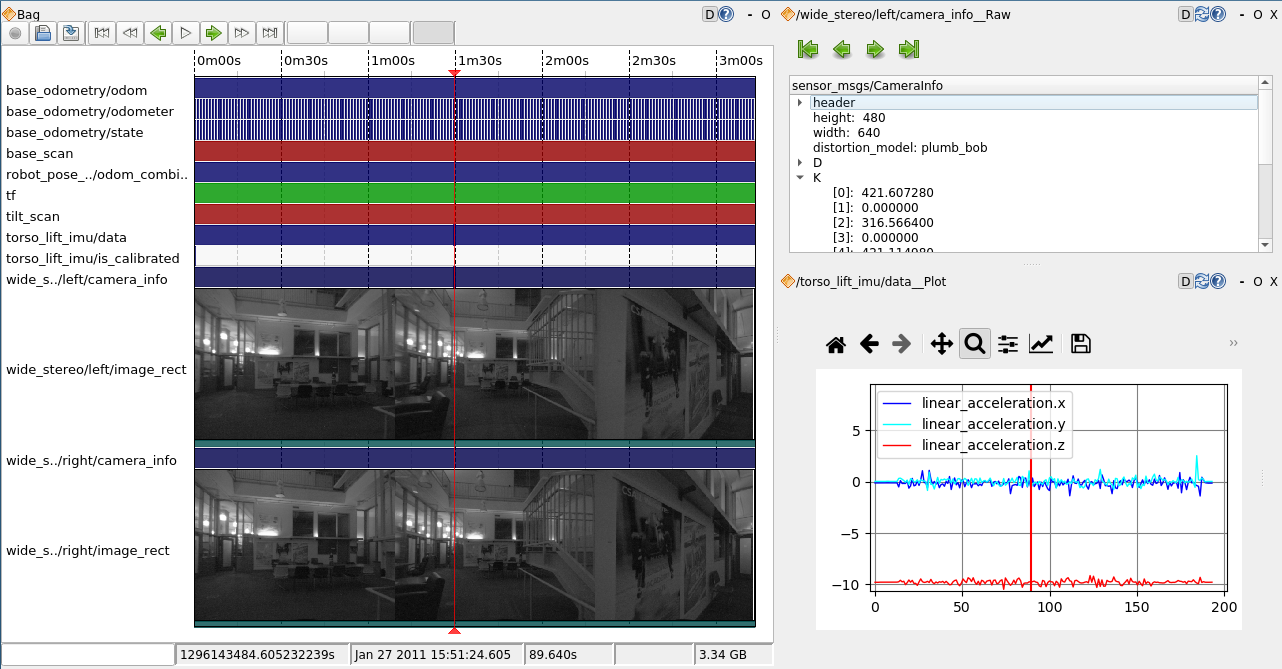 A Screenshot from the
A Screenshot from the  Overview of the
Overview of the